Students can easily access the best AI Class 10 Notes Chapter 6 Natural Language Processing Class 10 Notes for better learning.
Class 10 AI Natural Language Processing Notes
Natural Language Processing (NLP) refers to the AI method of communicating with an intelligent system using a natural language such as English.
The field of NLP involves making computers perform useful tasks using the natural languages humans use. The input and output of an NLP system can be –
Speech:
- Written Text
- What is NLP?
The ability of a computer to understand human language (commands) whether spoken or written and to generate an output by processing it, is called Natural Language Processing (NLP). It is a component of Artificial Intelligence.
![]()
Let’s understand it in simple words!:
Now question yourself why you are able to talk with your friend ?.. Because the words spoken by your friend are taken as input from your ears, your brain processes them and as an output, you respond and the most important thing the language you are using for communication is known to both of you. That’s NLP in simple words!

Components of NLP:
There are two components of NLP as given-
Natural Language Understanding (NLU):
Understanding involves the following tasks-
Mapping the given input in natural language into useful representations.
Analysing different aspects of the language.
Natural Language Generation (NLG):
It is the process of producing meaningful phrases and sentences in the form of natural language from some internal representation.
Natural Language Generation is a software process of generating natural language output from structured data sets. Its searches for the most relevant output from its network and after arranging it and checking the grammatical mistakes it feeds the best result to the user.
It is very ambiguous. There can be different levels of ambiguity:
Lexical ambiguity: It is at a very primitive level such as word level.
For example, treating the word “board” as a noun or verb?
Syntax Level ambiguity: A sentence can be parsed in different ways.
For example, “He lifted the beetle with a red cap.” Did he use cap to lift the beetle or he lifted a beetle that had red cap?
Referential ambiguity: Referring to something using pronouns. For example, Rima went to Gauri. She said, “I am tired.” Exactly who is tired?
One input can mean different meanings. Many inputs can mean the same thing.

It involves:
- Text Planning
- Sentence Planning
- Text Realisation
Text planning-It includes retrieving the relevant content from knowledge base.
Sentence planning-It includes choosing required words, forming meaningful phrases, setting tone of the sentence.
Text Realisation-It involves mapping the sentence plan into the sentence sentence structure.
![]()
Steps to be enumerated as:
- Content determination
- Data interpretation etc.
Steps in NLG:
Content determination: showing only important information or summary for the user’s speech. For example, Google shows only a summary for a Wikipedia search.
Data interpretation: Identifying the correct data and showing it to the user with the context of the input. For Example: In a Cricket match, winners, a man of the match, run rate of the teams.
Sentence Aggregation: The selection of words or expressions in an output sentence. For Example Selection between synonyms such as brilliant or fantastic.
Grammaticalisation: As the name suggests, it ensures the output must be according to grammatical patterns and does not have any grammatical mistakes in it. For Example: Using “,” between the text
Language Implementation: Ensuring the output data according to the user’s preferences and putting it into templates.For Example: When you asked something to Google Assistant, the words or sentences spoken by you is taken as input from your microphone then the Google Assistant recognises your speech and understands it (NLU) then it thinks of an answer (NLG), and after it gives you most relevant ones (output) for your queries!
Challenges in NLG:
- It should be Intelligence and Conversational.
- Deal with structured data
- Text/Sentence planning
NLP Terminology:
- Phonology: It is study of organising sound systematically.
- Morphology: It is a study of construction of words from primitive meaningful units.
- Morpheme: It is primitive unit of meaning in a language.
- Syntax: It refers to arranging words to make a sentence. It also involves determining the structural role of words in the sentence and in phrases.
- Semantics: It is concerned with the meaning of words and how to combine words into meaningful phrases and sentences.
- Pragmatics: It deals with using and understanding sentences in different situations and how the interpretation of the sentence is affected.
- Discourse: It deals with how the immediately preceding sentence can affect the interpretation of the next sentence.
- World Knowledge: It includes the general knowledge about the world.
![]()
Steps in NLP:
There are general five steps: Lexical Analysis: It involves identifying and analysing the structure of words. Lexicon of a language means the collection of words and phrases in a language. Lexical analysis is dividing the whole chunk of txt into paragraphs, sentences, and words.
Syntactic Analysis (Parsing): It involves analysis of words in the sentence for grammar and arranging the words in a manner that shows the relationship among the words. The sentence such as “The school goes to boy” would be rejected by English syntactic’ analyser.

Semantic Analysis: It draws the exact meaning or the dictionary meaning from the text. The text is checked for meaningfulness. It is done by mapping syntactic structures and objects in the task domain. The semantic analyser disregards a sentence such as “hot ice-cream”.
Discourse Integration: The meaning of any sentence depends upon the meaning of the sentence just before it. In addition, it also contributes to the meaning of the immediately succeeding sentence.
Pragmatic Analysis: During this step, what was said is re-interpreted to comprehend its intended meaning. It involves deriving those aspects of language which require real-world knowledge.
Applications of NLP:
It is a subfield of artificial intelligence (AD) that deals with the interaction between computers and humans using natural language. NLP enables machines to understand, interpret, and generate human language. Here are some examples of NLP applications:
Sentiment analysis: This involves analysing text to determine the sentiment expressed in it, such as positive, negative, or neutral. For example, a company might use sentiment analysis to monitor social media to understand how people feel about their products or services.
Machine Translation: This involves automatically translating text from one language to another. For example, Google Translate uses NLP techniques to translate text from one language to another.
![]()
Named Entity Recognition: This involves identifying and extracting named entities from text, such as names of people, places, and organisations. For example, a news organisation might use named entity recognition to automatically extract the names of people and organisations from news articles.
Question Answering: This involves answering questions posed by users using natural language. For example, a virtual assistant like Siri or Alexa uses NLP techniques to answer questions posed by users.
Chatbots: This involves creating computer programs that can converse with users in natural language. For example, a customer service chatbot can help customers resolve their queries by conversing with them in natural language.
Two types of chatbots are:
Script-bots: Script-bots follow a set of instructions already given to them. They are easy to create and use because they stick to a simple plan. You can think of them like robots following a script in a play.Script-bots are like actors reading lines from a script-they do what they’re told and don’t change their performance. .
Smart-bots: Smart-bots are like students who learn and adapt as they go. They use a lot of information to make decisions, just like when you study for a test.
Smart-bots can handle more complicated tasks and can change their behaviour based on what’s happening. While they’re more powerful, they need more work to set up and use because they’re like students who need to learn and grow over time. Technically, the main task of NLP would be to program computers for analysing and processing huge amount of natural language data.
![]()
These are just a few examples of NLP applications. NLP is a rapidly growing field, and there are many other applications, such as text classification, information. extraction, and summarisation.
Key applications of NLP:
Speech Recognition : Speech recognition is when a system is able to give output by understanding or interpreting a user’s speech as an input or a command. Used in: Google Assistant, Apple Siri, Amazon Alexa, etc.
Sentimental Analysis : Sentimental Analysis is a process of detecting bad and positive sentiments in a text. Used in: Youtube’s violent or graphic content policies, review of products, identifying spam messages.
Machine Translations : Translations of text in a language to another different language by machines. Used in: Google Translate, Youtube cc, Chatbot(s), etc.
After the Applications of NLP:
Revisiting the AI Project Cycle: Building a Natural Language Processing Project
Let’s explore the process of developing a Natural Language Processing (NLP) project within the context of stress management using Cognitive Behavioural Therapy (CBT) as an intervention method. Stress is a prevalent issue affecting individuals due to various factors such as academic pressure, social expectations, family dynamics, and personal relationships. To address this, CBT emerges as a promising approach known for its effectiveness in helping individuals cope with stressors and improve their mental well-being. Now, let’s delve into the project cycle:
Problem Scoping: In the initial phase of the project, it’s essential to comprehensively scope the problem of stress management and intervention. This involves identifying the individuals experiencing stress, understanding the nature of their stressors, determining where stress manifests in their lives, and elucidating the reasons behind their stress.
Who Canvas: Identifying individuals affected by stress and potential beneficiaries of CBT intervention.
What Canvas: Understanding the nature and triggers of stress experienced by individuals.
Where Canvas: Identifying the environments or contexts where stress manifests and interventions are needed.
Why Canvas: Exploring the underlying reasons and consequences of stress, emphasising the importance of effective intervention strategies.
![]()
Data Acquisition: Includes gathering conversational data from individuals undergoing stress or receiving CBT. Data collection methods include surveys, interviews, online forums, and therapy sessions. Each data source provides valuable insights into the language patterns and sentiments associated with stress and therapeutic interactions. The collected data serves as the foundation for developing NLP models to analyse and understand the language used in stress-related contexts.
Data Exploration: Processing and cleaning the collected textual data to prepare it for NLP analysis. Cleaning text data for NLP analysis. Making text consistent using normalisation methods. Studying data to find language patterns, emotions, and stress-related cues. This helps understand how language affects therapy.
Modelling: Feeding the preprocessed textual data to train NLP models for stress analysis and therapy. Using Al to build models that find stress signs, analyse coping methods, and track therapy progress. Trying different NLP methods like sentiment analysis and topic modeling to improve therapy effectiveness. Choose the models based on project goals and therapy needs.
Evaluation: Assessing how well NLP models analyse stress language and aid therapy by comparing their predictions with clinical observations. Gathering user feedback to confirm the usefulness of NLP in stress management, continuously refining NLP models to ensure their effectiveness in real-world applications.
Evolution of NLP:
We have divided the history of NLP into four phases. The phases have distinctive concerns and styles.
First Phase (Machine Translation Phase) Late 1940s to late 1960s :
- The work done in this phase focused mainly on machine translation (MT). This phase was a period of enthusiasm and optimism.
- Let us now see all that the first phase had in it-
- The research on NLP started in early 1950s after Booth & Richens’ investigation and Weaver’s memorandum on machine translation in 1949.
- 1954 was the year when a limited experiment on automatic translation from Russian to English demonstrated in the Georgetown-IBM experiment.
- In the same year, the publication of the journal MT (Machine Translation) started.
- The first international conference on Machine Translation (MT) was held in 1952 and second was held in 1956.
- In 1961, the work presented in Teddington International Conference on Machine Translation of Languages and Applied Language analysis was the high point of this phase.
Second Phase (AI Influenced Phase): Late 1960s to late 1970s :
In this phase, the work done was majorly related to world knowledge and on its role in the construction and manipulation of meaning representations. That is why, this phase is also called AI-flavored phase.
The phase had in it, the following:
In early 1961, the work began on the problems of addressing and constructing data or knowledge base. This work was influenced by AI.
In the same year, a BASEBALL question-answering system was also developed. The input to this system was restricted and the language processing involved was a simple one.
![]()
A much advanced system was described in Minsky (1968). This system, when compared to the BASEBALL question-answering system, was recognised and provided for the need of inference on the knowledge base in interpreting and responding to language input.
Third Phase (Grammatico-logical Phase): Late 1970s to late 1980s :
This phase can be described as the grammatico-logical phase. Due to the failure of practical system building in last phase, the researchers moved towards the use of logic for knowledge representation and reasoning in AI.
The third phase had the following in it: The grammatico-logical approach, towards the end of decade, helped us with powerful general-purpose sentence processors like SRI’s Core Language Engine and Discourse Representation Theory, which offered a means of tackling more extended discourse.
In this phase we got some practical resources & tools like parsers, e.g. Alvey Natural Language Tools along with more operational and commercial systems, e.g. for database query.
The work on lexicon in 1980 s also pointed in the direction of grammatico-logical approach.
Fourth Phase (Lexical & Corpus Phase): The 1990s :
We can describe this as a lexical & corpus phase. The phase had a lexicalised approach to grammar that appeared in late 1980s and became an increasing influence. There was a revolution in natural language processing in this decade with the introduction of machine learning algorithms for language processing.
Human Language VS Computer Language:
Humans use different languages to communicate with each other seamlessly.Our brains keep processing the words that it listens to and the actions that it sees.it tries to make sense by analysing all of this at the same time via the processing of speech signals through the eardrums and visual signals from the eyes.
![]()
Computers on the other hand understand only binary language.Unlike humans,machines are not able to catch the errors while typing, hence it may not process that part at all.
Study of Human Languages:
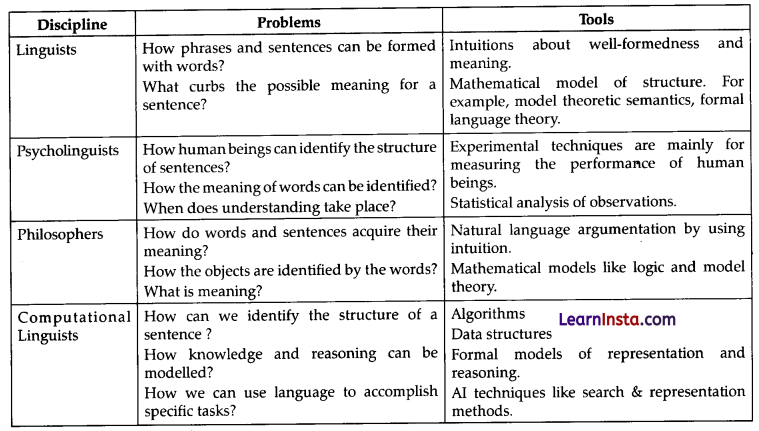
Language is a crucial and fundamental aspect of human behaviour. We can experience it in mainly two forms –
written and spoken. In written form, it is a way to pass our knowledge from one generation to the next. In the spoken form, it is the primary medium for human beings to coordinate with each other in their day-today behaviour. Language is studied in various academic disciplines. Each discipline comes with its own set of problems and a set of solutions to address those.
Consider the following table to understand this:
Ambiguity and Uncertainty in Language:
Ambiguity, a concept commonly heard in NLP, can be referred to as the ability to interpret a sentence or expression in multiple ways. In simple terms, we can say that ambiguity is the capability of being understood in more than one way. Natural language is very ambiguous. NLP has the following types of ambiguities
Lexical Ambiguity:
The ambiguity of a single word is called lexical ambiguity , in other words,this occurs when a single word can have multiple meanings. For example, treating the word ‘silver’ as a noun, an adjective, or a verb.
![]()
Semantic Ambiguity:
This kind of ambiguity occurs when the meaning of the words themselves can be misinterpreted. In other words, semantic ambiguity happens when a sentence contains an ambiguous word or phrase. For example, the sentence “The car hit the pole while it was moving is having semantic ambiguity because the interpretations can be “The car while moving, hit the pole” and “The car hit the pole while the pole was moving”.
Anaphoric Ambiguity:
This kind of ambiguity arises due to the use of anaphora entities in discourse or in other words where subsequent sentences refer back to earlier entities in a way that can lead to confusion. For example, the horse ran up the hill. It was very steep. It soon got tired. Here, the anaphoric reference of “it” in two situations causes ambiguity.
Pragmatic ambiguity:
Such kind of ambiguity refers to a situation where the context of a phrase gives it multiple interpretations. In simple words, we can say that pragmatic ambiguity arises when the statement is not specific. For example, the sentence “I like you too” can have multiple interpretations like I like you (just like you like me), I like you (just like someone else dose).
NLP Phases:
Following diagram shows the phases or logical steps in natural language processing:
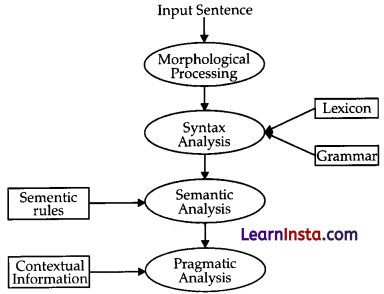
Morphological Processing:
It is the first phase of NLP. The purpose of this phase is to break chunks of language input into sets of tokens corresponding to paragraphs, sentences and words. For example, a word like “uneasy” can be broken into two sub-word tokens as “un-easy”.
Syntax Analysis:
It is the second phase of NLP. The purpose of this phase is two folds: first, to check that a sentence is well formed or not and second to break it up into a structure that shows the syntactic relationships between the different words. For example, a sentence like “The school goes to the boy” would be rejected by a syntax analyser or parser.
![]()
Semantic Analysis:
It is the third phase of NLP. The purpose of this phase is to draw exact meaning, or you can say dictionary meaning from the text. The text is checked for meaningfuhess. For example, a semantic analyser would reject a sentence like “Hot ice cream”.
Pragmatic Analysis:
It is the fourth phase of NLP. Pragmatic analysis simply fits the actual objects/events, which exist in a given context with object references obtained during the last phase (semantic analysis). For example, the sentence “Put the banana in the basket on the shelf” can have two semantic interpretations and the pragmatic analyser will choose between these two possibilities.
Natural Language Understanding (NLU):
Collecting the information and understanding it, is called Natural Language Understanding (NLU).
Natural Language Understanding (NLU) uses algorithms to convert data spoken or written by the user into a structured data model. It does not require an in-depth understanding of the input but the Process Of NLP Natural Language Understanding (NLU) uses algorithms to convert data spoken or written by the user into a structured data model. It does not require an in-depth understanding of the input but has to deal with a much larger vocabulary.
Two subtopics of NLU:
Intent recognition: It is the most important part of NLU because it is the process of identifying the user’s intention in the input and establishing the correct meaning.
Entity recognition: It is the process of extracting the most important data in the input such as name, location, places, numbers, date, etc. For example: What happened on 9 / 11 (date) in the USA (place)1. Intent recognition: It is the most important part of NLU because it is the process of identifying the user’s intention in the input and establishing the correct meaning.
Humans communicate through language which we process all the time. Our brain keeps on processing the sounds that it hears around itself and tries to make sense out of them all the time.
On the other hand, the computer understands the language of numbers. Everything that is sent to the machine has to be converted to numbers. And while typing, if a single mistake is made, the computer throws an error and does not process that part. The communications made by the machines are very basic and simple.
![]()
TFDIF:
TF-IDF (Term Frequency-Inverse Document Frequency) is a technique used in natural language processing to determine the importance of words in a document corpus. Here are some key points about TF-IDF and its applications:
Term Frequency (TF): It measures the frequency of a term in a document. Words that appear more frequently within a document are considered more important for that document.
Inverse Document Frequency (IDF): It evaluates the rarity of a term across all documents in a corpus. Rare terms that appear in fewer documents are considered more valuable.
TF-IDF Calculation: TF-IDF combines both TF and IDF to assign a weight to each term in a document. The formula multiplies the term frequency with the inverse document frequency, resulting in a higher weight for terms that are frequent in a document but rare across the corpus.
Applications of TFDIF:
- Document Classification: Identifying key features to classify documents into different categories.
- Topic Modelling: Highlighting significant terms to reveal prevalent themes across documents.
- Information Retrieval: Ranking documents based on relevance to search queries.
- Stop Word Filtering: Removing common words that carry little meaning.
- Keyword Extraction: Identifying important keywords within documents.
![]()
Benefits of TF-IDF:
- It provides a quantitative measure of term importance.
- It helps in identifying relevant terms for various text analysis tasks.
- It is computationally efficient and widely used in practice.